每一次系統發生 bug,都需要調 log 才能知道到底錯在哪裡
目前的做法都是 SSH 進去 ec2 instance 把 log 抓出來給工程師
這種動作本身就需要時間,再加上每個人工作時程的安排,會明顯地拉長 debug cycle
為了改善這個問題,架設一套自動蒐集、保管 log 的系統就成了非常值得的投資
Loki 切中我的需求,但關於如何單機架設的文章似乎不多
本篇文章描述如何在 ec2 instance 用 docker-compose 架設 Grafana + Loki
再順便裝個 Prometheus
Grafana? Loki? Prometheus?
- Grafana 提供網頁介面,可以串接各種資料來源,另外有各種現成 dashboard
- Loki 專門用來蒐集 log,與 Elasticsearch 的差別在:Loki 不會對每一筆 log 做索引,因此輕量很多
- Prometheus 用來蒐集機器產生的各種指標(如 Sys load、RAM used),並由 Grafana 讀取並繪製成漂亮的 dashbaord
架構
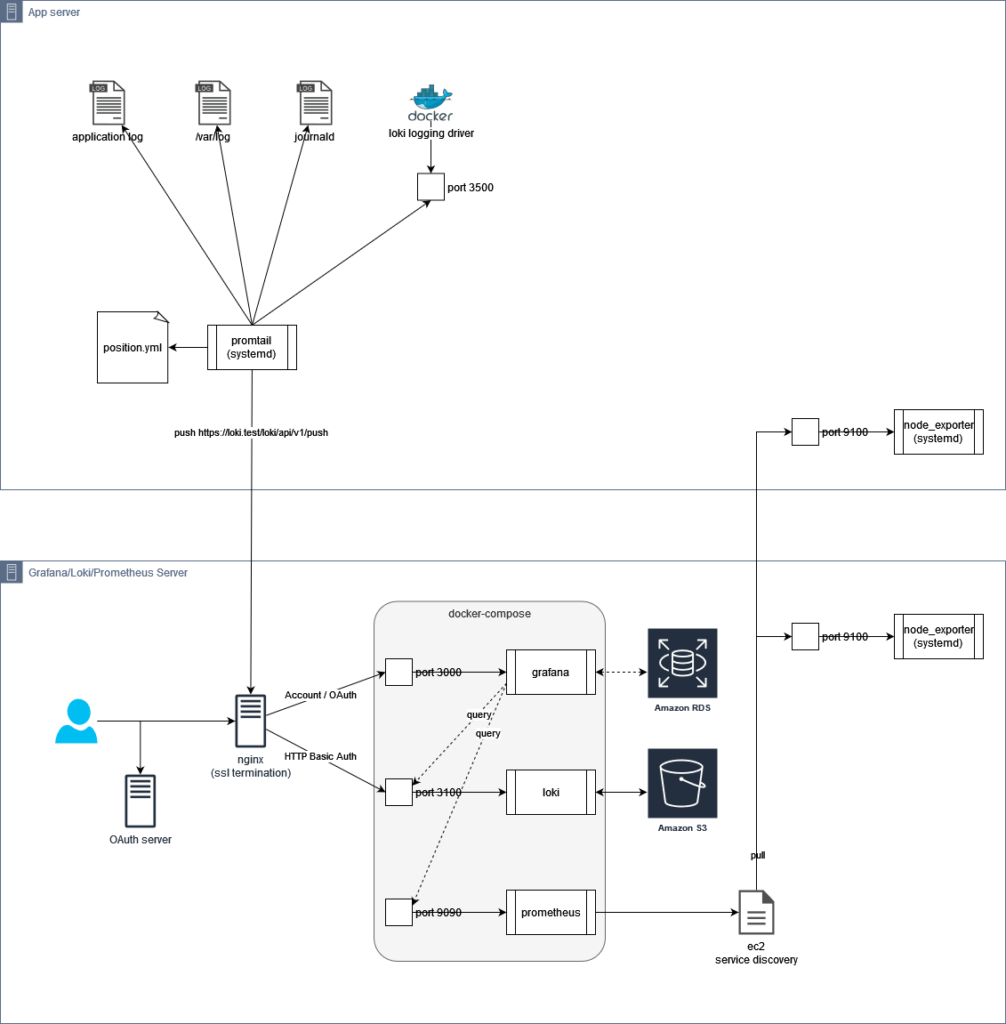
在每一個 application server 上需要架設:
- promtail
- 作用:蒐集各種 log 並傳給 Loki
- node_exporter
- 提供各種系統指標,並開放讓 Prometheus 來讀取
在 Grafana server 上需要架設:
- docker-compose service
- nginx container
- 作用:提供 HTTPS 連線、SSL Termination,並用 nginx auth_basic 以及 htpasswd 保護 Loki
- grafana container
- loki container
- prometheus container
- 只對本機開放連線
- 透過 ec2_sd_configs 掃描 instance 並去蒐集 metrics。
- nginx container
- node_exporter
為了 Grafana server 需要在 AWS 上建立:
- S3 bucket
- S3 Gateway endpoint
- IAM Role
- EC2 instance
- Security group
- DNS record
需要考慮的點
Storage
我的目標有:Cost effective、moderate availability、資料至少儲存 15 天
所以會優先把資料存到好用且便宜的 storage(如S3),不然就直接存硬碟上(如EBS)
Loki 可以把 chunk/index 壓縮並存到 S3
compactor 還會定期把每日產生的 96 個 index file 打包起來
不僅降低讀取 chunk/index 時的掃描量,也降低 GetObject 帶來的高額花費
不過實際表現仍然要觀察(有文章指出可能有 unforeseen bill)
Prometheus 在 Operation aspect 頁面有描述以下幾點:
- 預設保留 15 天的資料
- 可以指定最大使用容量
- 容量可以用下列公式估計

假設要保存 15 天
並且有 20 台 EC2 instance 使用 Node exporter 每次輸出 1513 個 sample
Prometheus 會每隔 15 秒去抓一次
每個 sample 假設是 2bytes
所以
retention_time_seconds = 15 days * 86400 seconds = 1296000
ingested_samples_per_second = 20 * 1513 / 15 = 2017.4
bytes_per_sample = 2 bytes
needed_disk_space = 1296000 * 2017.4 *2 = 5229100800 bytes = 5.229 GB
那應該 10 GB 的 EBS volume 就很夠用了?🤔
Network
另外 EC2 與 S3 之間的傳輸一定要用 Gateway endpoint,讓流量維持在 AWS 內部
(應該可以)降低延遲、提高安全性、降低流量費用
Compute
EC2 Instance type 就先用 t3a 系列
(因為 Loki、Prometheus 都是間歇性的接收資料,CPU 只會在接收資料的時候高一點)
EBS 容量就是視情況加大
Availability
關於 EC2、EBS 的可用性
EC2 在 2022/3/30 剛宣布預設開啟 auto recovery 功能,如果出狀況會自動轉移到新的 rack
EBS 可用性是 99.999%,會在 AZ 內有複本,應該很可靠,只怕容量不夠用
參考
-
在 ubuntu 安裝 node exporter:
sudo apt install prometheus-node-exporter