最近花很多力氣優化 msgpack-nodejs 這個專案
參考了其他先進的優化策略、把效能拉到跟當時 nodejs 生態圈最快的專案同等級
但不夠多自己原創的東西,也還是覺得有優化空間,所以還是努力一點一滴的累積優化
終於在今天,撇除跑分太鬼的 msgpackr,編碼速度贏了 22%、解碼速度贏 19%,覺得終於可以休息了
這邊文章是想在把這些細節遺忘前做點紀錄
msgpack-javascript 的 src/Encoder.ts 給了我相當大的啟發,他做的事情大概是:
-
utf8Count() 計算字串的UTF8編碼總共要幾 Bytes
-
ensureBufferSizeToWrite() 確定目前 Buffer 有足夠的寫入空間
-
writeStringHeader() 寫入 Spec 規定的 String header、字串長度
-
utf8EncodeTE() 或 utf8EncodeJs() 對字串編碼,根據 nodejs 版本,可能使用到 encodeInto()
-
this.pos += byteLength;移動指針
上述動作中,2、3、5 都是各個相關專案會出現的操作,但 1、4 很特別
首先講 4 ,自己刻UTF8編碼的原因應該是:
TextDecoder 在解碼小於 200 Bytes 的 UTF8 資料時特別慢
但我自己也這樣做過,因為當時有寫 benchmark 且發現沒效益才放棄
但是其中動用到 encodeInto() 的部分會比較特別,因為這個 API 能把編碼結果寫到指定的 Uint8Array 裡面,不會回傳編碼後的資料,也許是因為少了編碼過程中的 buffer resize 所以效能可能好一點。但它有個問題:無法在編碼前得知編碼後的 byteLength。所以該專案才會有下面要講的第 1 步驟。
再來講 1,他這麼做的主因應該是:
想要得到 encodeInto() 的效能優勢,但 Spec 要求先寫字串長度,才能寫 UTF8 bytes
所以乾脆自己先把長度算出來
個人認為這樣不值得
因為 utf8Count 的實作與 utf8EncodeJs 雷同,都是一個一個 bytes 讀過去
但一個是把 char code 轉換成 UTF8 編碼;一個是把所需 bytes 數量加總後回傳
跑這兩個 function 幾乎等於做兩次編碼,所以我覺得找其他方式會比較好
我也想得到encodeInto() 的效能優勢,但不想要自己計算長度
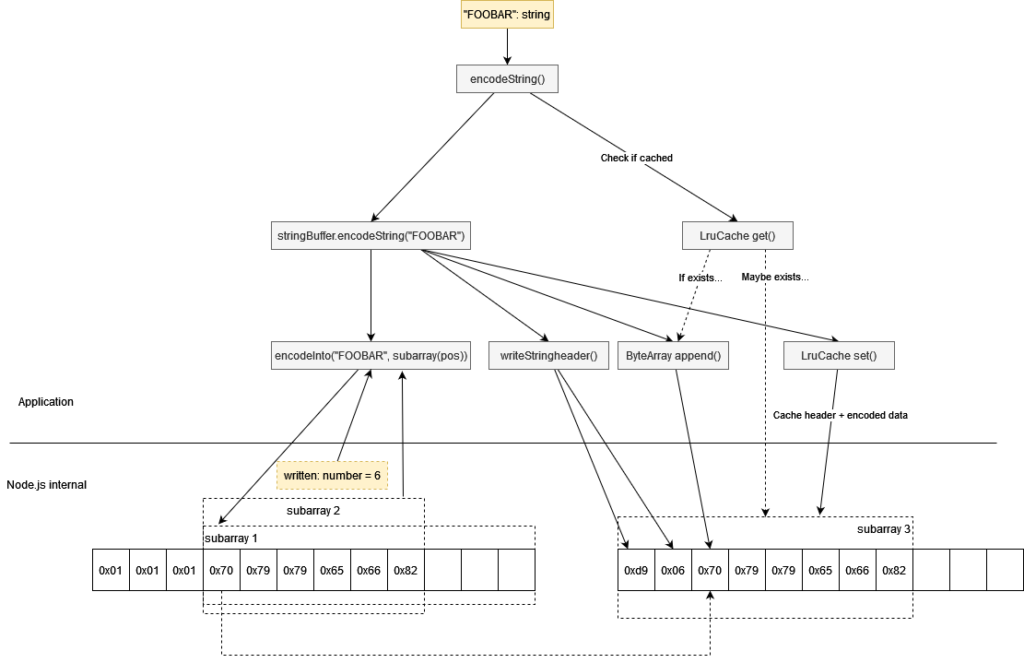
我用encodeInto() 先把結果寫進 StringBuffer,接著利用 API 回傳的 written bytes,對編碼結果用 subarray() 重新建立 View(這麼做不會複製任何 data bytes),而這個 View 就能用來取得編碼後的長度以及資料。
長度用 writeStringHeader() 寫入、資料用 ByteArray append() 寫入
而 append() 裡面用到的 TypedArray set(),MDN 說會用很智慧的方式複製資料(?)
整個流程如這樣 src/encoder/encoder.ts#L203-L225
然後再加上 LruCache 避免對一樣的字串再跑一次這些運算
整體流程像這樣: